robustness similarity improving attention
MEANTIME Mixture of Attention Mechanisms with Multi-temporal Embeddings for Sequential Recommendation
[TOC] > [Cho S., Park E. and Yoo S. MEANTIME: Mixture of attention mechanisms with multi-temporal embeddings for sequential recommendation. RecSys, 20 ......
LEA: Improving Sentence Similarity Robustness to Typos Using Lexical Attention Bias 论文阅读
# LEA: Improving Sentence Similarity Robustness to Typos Using Lexical Attention Bias 论文阅读 KDD 2023 [原文地址](https://arxiv.org/abs/2307.02912) ## Introd ......
【论文阅读】CrossViT:Cross-Attention Multi-Scale Vision Transformer for Image Classification
> # 🚩前言 > > - 🐳博客主页:😚[睡晚不猿序程](https://www.cnblogs.com/whp135/)😚 > - ⌚首发时间:23.7.10 > - ⏰最近更新时间:23.7.10 > - 🙆本文由 **睡晚不猿序程** 原创 > - 🤡作者是蒻蒟本蒟,如果文章里有 ......
CF1817C Similar Polynomials
直接带入 $$ \begin{aligned} \sum_{i=0}^{d}b_ix^i&=\sum_{i=0}^{d}a_i(x+s)^{i}\\ &=\sum_{i=0}^{d}x_i\sum_{j=i}^{d}\binom{j}{i}a_js^{j-i}\\ \end{aligned} $$ ......
Codeforces 1257F Make Them Similar
发现 $O(2^w)$ 过不了但是 $O(2^{\frac{w}{2}})$ 过得了($w$ 为数二进制形式位数,此题为 $30$),且异或操作表明每一位之间不会互相影响,很明显上个折半搜索就行。 考虑怎么合并,和 CF585D 同样的套路,考虑前半部分得到的为 $c_{1\sim n}$,后半部分 ......
Multi-Modal Attention Network Learning for Semantic Source Code Retrieval 解读
# Multi-Modal Attention Network Learning for Semantic Source Code Retrieva Multi-Modal Attention Network Learning for Semantic Source Code Retrieval,题 ......
【论文阅读】CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention
来自CVPR 2021 论文地址:https://link.zhihu.com/?target=https%3A//arxiv.org/pdf/2108.00154.pdf 代码地址:https://link.zhihu.com/?target=https%3A//github.com/cheers ......
Spike timing reshapes robustness against attacks in spiking neural networks
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 同大组工作 ......
4.1 Self-attention
# 1. 问题引入 我们在之前的课程里遇到的都是输入是一个向量,输出是类别或者标量.但如果输入是向量的集合且向量长度还会变化,又应该怎么处理呢? ** 是标量场上的滑动窗口内的加权平均,数学上等价于卷积。[^WMA] [2] **Kernel Smoother** 是一种特殊的 WMA 方法,特殊在于权重是由**核函数**决定的,相互之间越接近的点具有越高的权 ......
Attention is All you need
转载:https://zhuanlan.zhihu.com/p/46990010 Attention机制最早在视觉领域提出,2014年Google Mind发表了《Recurrent Models of Visual Attention》,使Attention机制流行起来,这篇论文采用了RNN模型, ......
VINS-Mono: A Robust and Versatile Monocular Visual-Inertial State Estimator-翻译
摘要:本文介绍了一种单目视觉惯性系统(VINS),用于在各种环境中进行状态估计。单目相机和低成本惯性测量单元(IMU)构成了六自由度状态估计的最小传感器套件。我们的算法通过有界滑动窗口迭代地优化视觉和惯性测量,以实现精确的状态估计。视觉结构是通过滑动窗口中的关键帧来维护的,而惯性度量则是通过关键帧之 ......
Self-attention with Functional Time Representation Learning
[TOC] > [Xu D., Ruan C., Kumar S., Korpeoglu E. and Achan K. Self-attention with functional time representation learning. NIPS, 2019.](http://arxiv.or ......
Time Interval Aware Self-Attention for Sequential Recommendation
[TOC] > [Li J., Wang Y., McAuley J. Time interval aware self-attention for sequential recommendation. WSDM, 2020.](https://dl.acm.org/doi/10.1145/3336 ......
SNN-RAT: Robustness-enhanced Spiking Neural Network through Regularized Adversarial Training
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 同大组工作 Abstract ......
attention学习-课程笔记
attention层计算过程: 相似度函数fatt计算输入X和查询向量q之间的相似度e; 相似度e经过softmax计算得到权重 a。 向量e和a的长度与输入X的第一个维度相同。 权重a与输入X相乘,得到输出y。 相似度计算可使用 点积dot prodecut,由于输入X的维度通常较高,q.X值会很 ......
Attention、Self-Attention 与 Multi-Head Attention
Corpus语料库与DB数据库 World Knowledge世界常识库:OALD牛津高阶/Synonyms/Phrases/…, 新华字典/成语词典/辞海, 行业词典,大英百科,Wikipedia,… 全局信息: Corpus语料库、行业通用数据库(例如Springer/Google Schola ......
业务场景(用户交互) + Corpus语料库/数据库建立 + Attention 与 Self-Attention:世界常识库|全局信息|语法信息|句法信息|Context上下文信息
一、场景(用户交互): 1. 用户发起新会话Session,初始化交互系统,等待 用户输入 或 传入任务文档; 2. 用户实时输入,触发实时交互,设当前输入句子为S: 当前输入句子 S 长度未定,并且可能是动态字符流式输入: 因此可以用 Sliding Window滑动窗口, 提取 当前输入单词Wo ......
Occupancy Grid Map to Pose Graph-based Map: Robust BIM-based 2D- LiDAR Localization for Lifelong Indoor Navigation in Changing and Dynamic Environments
将占据栅格地图转换为基于姿态图的地图:基于BIM的2D LiDAR定位在变化和动态环境中实现终身室内导航的鲁棒性。 摘要: 许多研究都依赖于事实上的标准自适应蒙特卡罗定位(AMCL)方法,以在从建筑信息模型(BIM模型)提取的占用栅格地图(OGM)中定位机器人。然而,大多数这些研究都假设BIM模型准 ......
01.Self—attention
self—attention 自注意力机制 一、输入 在学习自注意力机制之前,我们学到的神经网络的输入都是一个向量,输出可能是一个数值或者是一个类别。 1.举个例子。假设输入的向量是一排向量,而且输入的向量的数目是会改变的, 最简单的输入长度会改变的向量就是文字处理,假设我们的输入是一个句子的话。 ......
Muesli: Combining Improvements in Policy Optimization
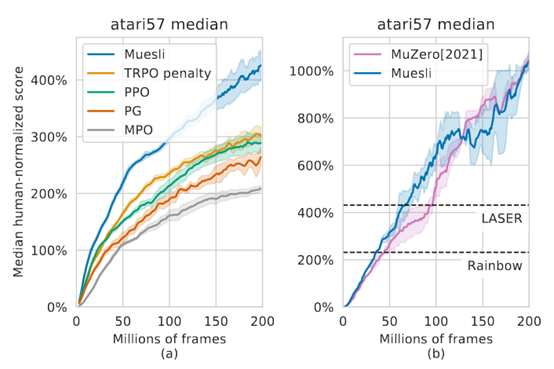 **发表时间:**2021(ICML 2021) **文章要点:**这篇文章提出一个更新policy的方式,结合 ......
关于vi编辑出现E325: ATTENTION的解决方案
解决方案 1 - vi filename进入编辑器,查看报错信息,出现E325: ATTENTION 例如:E325: ATTENTION Found a swap file by the name "rm /var/opt/gitlab/gitlab-rails/etc/.gitlab.yml.s ......
Self-consistency Improves Chain of Thought Reasoning in Language Models 论文阅读
ICLR 2023 [原文地址](https://arxiv.org/abs/2203.11171) ## 1. Motivation Chain-of-Thought(CoT)使Large Language Models(LLMs)在复杂的推理任务中取得了令人鼓舞的结果。 本文提出了一种新的解码策 ......
Neural Attentive Session-based Recommendation
[TOC] >[ Li J., Ren P., Chen Z., Ren Z., Lian T. and Ma J. Neural attentive session-based recommendation. CIKM, 2017.](http://arxiv.org/abs/1711.04725 ......
POLICY IMPROVEMENT BY PLANNING WITH GUMBEL
 **发表时间:**2022(ICLR 2022) **文章要点:**AlphaZero在搜索次数很少的时候甚至动 ......
[论文阅读] Few-shot Font Generation by Learning Style Difference and Similarity
## Pre title: Few-shot Font Generation by Learning Style Difference and Similarity accepted: Arxiv 2023 paper: https://arxiv.org/abs/2301.10008 code: ......
[论文阅读] DGFont++ Robust Deformable Generative Networks for Unsupervised Font Generation
## Pre title: DGFont++: Robust Deformable Generative Networks for Unsupervised Font Generation accepted: Arxiv 2022 paper: https://arxiv.org/abs/2212. ......
Efficient Graph Generation with Graph Recurrent Attention Networks
[TOC] > [Liao R., Li Y., Song Y., Wang S., Nash C., Hamilton W. L., Duvenaud D., Urtasun R. and Zemel R. NIPS, 2019.](http://arxiv.org/abs/1910.00760) ......
Learning Affinity from Attention: End-to-End Weakly-Supervised Semantic Segmentation with Transformers概述
0.前言 相关资料: arxiv github 论文解读 论文基本信息: 领域:弱监督语义分割 发表时间: CVPR 2022(2022.3.5) 1.针对的问题 目前主流的弱监督语义分割方法通常首先训练分类模型,基于类别激活图(CAM)或其变种生成初始伪标签;然后对伪标签进行细化作为监督信息训练一 ......